
Redirects are a way of moving a webpage visitor from an old address to a new one without further action from them. Each webpage has a unique reference, a URL, to enable browsers to request the correct information be returned.
If a browser requests a page that has a redirect on it, it will be instructed to go to a different address. This means that the content on the original page is no longer available to request, and the browser must visit the new page to request the content there instead.
Essentially, redirects are instructions given to browsers or bots that the page they are looking for can no longer be reached and they must go to a different one instead.
Types of redirects
A website can indicate that a resource is no longer available at the previous address in several ways.
Permanent and temporary
When identifying that a redirect has been placed on a URL, search engines must decide whether to begin serving the new URL instead of the original in the search results.
Google claims it determines whether the redirect will be a permanent addition to the URL or just a temporary change in the location of the content.
If Google determines that the redirect is only temporary, it will likely continue to show the original URL in the search results. If it determines that the redirect is permanent, the new URL will begin to appear in the search results.
Meta refresh
A meta refresh redirect is a client-side redirect. This means that when a visitor to a site encounters a meta redirect, it will be their browser that identifies the need to go to a different page (unlike server-side redirects, where the server instructs the browser to go to a different page).
Meta refreshes can happen instantly or with a delay. A delayed meta refresh often accompanies a pop-up message like “you will be redirected in 5 seconds”.
Google claims it treats instant meta refreshes as “permanent” redirects, and delayed meta refreshes as “temporary” redirects.
JavaScript redirect
A redirect that uses JavaScript to take users from one page to another is also an example of a client-side redirect. Google warns website managers to only use JavaScript redirects if they can’t use server-side redirects or meta-refresh redirects.
Essentially, search engines will need to render the page before picking up the JavaScript redirect. This can mean there may be instances where the redirect is missed.
Server-side redirects
By far, the safest method for redirecting URLs is server-side redirects.
This requires access to the website’s server configuration, which is why meta refreshes are sometimes preferred. If you can access your server’s config files, then you will have several options available.
The key differences in these status codes are whether they indicate the redirect is permanent or temporary and whether the request method of POST (used to send data to a server) or GET (used to request data from a server) can be changed.
For a more comprehensive overview of POST and GET and why they matter for different applications, see the W3schools explanation.
Permanent redirects
- 301 (moved permanently): A redirect that returns a HTTP status code of “301” indicates that the resource found at the original URL has permanently moved to the new one. It will not revert to the old URL and it allows the original request method to change from POST to GET.
- 308 (permanent redirect): A 308 server response code is similar to 301 in that it indicates that the resource found at the original URL has permanently moved to the new one. However, the key difference between the 308 and the 301 is that it recommends maintaining the original request method of POST or GET.
Temporary redirects
- 302 – found (temporarily displaced): A 302 server code indicates that the move from one URL to another is only temporary. It is likely the redirect will be removed at some point in the near future. As with the 301 redirect, browsers can use a different request method from the original (POST or GET).
- 307 (temporary redirect): A 307 server code also indicates that a redirect is temporary, but as with a 308 redirect it recommends retaining the request method of the original URL.
Why use redirects
There are several good reasons to use redirects. Just like you might send out change-of-address cards when moving house (well, back in the early 2000s anyway, I’m not sure how you kids do it now), URL redirects help ensure that important visitors don’t get lost.
Human website users
A redirect means that when accessing content on your site a human visitor is taken automatically to the more relevant page.
For example, a visitor may have bookmarked your URL in the past. They then click on the bookmark without realizing the URL has changed. Without the redirect, they may end up on a page with a 404 error code and no way of knowing how to get to the content they are after.
A redirect means you do not have to rely on visitors working out how to navigate to the new URL. Instead, they are automatically taken to the correct page. This is much better for user experience.
Search engines
Similar to human users, when a search engine bot hits a redirect, it is taken to the new URL.
Instead of leaving them on a 404 error page, it can identify the equivalent URL straightaway, negating the need for the search bot to try to identify where, if anywhere, that original URL’s content might now be housed.
Demonstrating equivalence
Search engines will use redirects to determine if they should continue displaying the original URL in the search results.
If there is no redirect from an old, defunct URL to the new one, then the search engines will likely just de-index the old URL as it has no value as a 404 page. With a redirect in place, however, the search engine can directly link the new URL to the old one.
- If it is redirected permanently, the search engine will likely begin to display the new URL in the search results.
- If it is a temporary redirect, they may continue to display the old one. Google and other search engines may pass some of the ranking signals from the old URL to the new one due to the redirect.
This only happens if they believe the new page to be the equivalent of the old one in terms of value to searchers.
There are instances where this will not be the case, however, usually because the redirects have been implemented incorrectly. More on that later.
Typical SEO use cases for redirects
There are some very common reasons why a website owner might want to implement redirects to help both users and search engines find content. Importantly for SEO, redirects can allow the new page to retain some of the ranking power of the old one.
Vanity URLs
Vanity URLs are often used to help people remember URLs. For example, a TV advert might tell viewers to visit www.example-competition.com to enter their competition.
This URL might redirect to www.example.com/competitions/tv-ad-2024, which is far harder for viewers to remember and enter correctly. Using a vanity URL like this means website owners can use short URLs that are easy to remember and spell without having to set up the content outside of their current website structure.
URL rewrites
There may be instances when a URL needs to be edited once it’s already live.
For example, perhaps a product name has changed, a spelling mistake has been noticed, or a date in the URL needs to be updated. In these cases, a redirect from the old URL to the new one will ensure visitors and search bots can easily find the new address.
Moving content
Restructuring your website might necessitate redirects.
For example, you may be merging subfolders or moving content from one subdomain to another. This would be a great time to use redirects to ensure that content is easily accessible.
Moving domains
Website migrations, like moving from one domain address to another, are classic uses of redirects. These tend to be done en masse, often with every URL in the site requiring a redirect.
This can happen in internationalization, like moving a website from a .co.uk ccTLD to a .com address. It can also be necessitated through a company rebrand or the acquisition of another website and a desire to merge it with the existing one.
There may even be a need to split a website into separate domains. All of these cases would be good candidates for redirects.
HTTP to HTTPS
Not as common now the internet has largely woken up to the need for security is the migration from HTTP to HTTPS.
You still might need to switch a site from an insecure protocol (HTTP) to a secure one (HTTPS) in some situations. This will likely require redirects across the entire website.
Dig deeper: What is technical SEO?
Redirect problems to avoid
The main consideration when implementing redirects is which type to use.
In general, server-side redirects are generally safest to use. However, the choice between permanent and temporary redirects depends on your specific situation.
There are more potential pitfalls to be aware of.
Loops
Redirect loops happen when two redirects directly contradict each other. For example, URL A is redirected to URL B; however, URL B has a redirect pointing to URL A. This makes it unclear which page is supposed to be visited.
Search engines won’t be able to determine which page is meant to be canonical and human visitors will not be able to access either page.
If a redirect loop is present on a site, you will encounter a message like the one below when you try to access one of the pages in the loop:
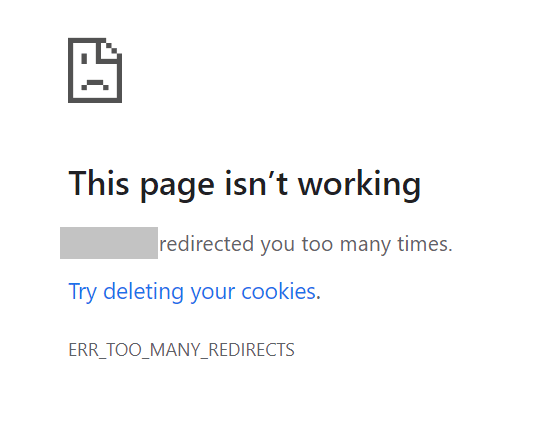
To fix this error, remove the redirects causing the loop and point them to the correct pages.
Chains
A redirect chain is a series of pages that redirect from one to another. For example, URL A redirects to URL B, which redirects to URL C, which redirects to URL D. This isn’t too much of an issue unless the chain gets too big.
URL chains can start to affect load speed. John Mueller, Search Advocate at Google, has also stated in the past that:
- “The only thing I’d watch out for is that you have less than 5 hops for URLs that are frequently crawled. With multiple hops, the main effect is that it’s a bit slower for users. Search engines just follow the redirect chain (for Google: up to 5 hops in the chain per crawl attempt).”
Soft 404s
Another problem that can arise from using redirects incorrectly is that search engines may not consider the redirect to be valid for the purposes of rankings.
For example, if Page A redirects to Page B but the two are not similar in content, the search engines may not pass any of the value of Page A to Page B. This can be reported as a “soft 404” in Google Search Console.
This typically happens when a webpage (e.g., a product page) is deleted and the URL is redirected to the homepage.
Anyone clicking on the product page from search results wouldn’t find the product information they were expecting if they landed on the homepage.
The signals and value of the original page won’t necessarily be passed to the homepage if it doesn’t match the user intent of searchers.
Ignoring previous redirects
It can be a mistake not to consider previously implemented redirects. Without checking to see what redirects are already active on the site, you may run the risk of creating loops or chains.
Frequent changes
Another reason for planning redirects in advance is to limit the need to frequently change them. It is important from an internal productivity perspective, especially if you involve other teams in their implementation.
Most crucially, though, is that you may find the search engines struggle to keep up with frequent changes, especially if you incorrectly suggest the redirect is permanent by using a 301 or 308 status code.
Good practice for redirects
It is helpful when considering any activity involving redirects to do the following to prevent problems down the road.
Create a redirect map
A redirect map is a simple plan showing which URLs should redirect and their destinations. It can be as simple as a spreadsheet with a column of “from” URLs and “to” URLs.
This way, you have a clear visual of what redirects will be implemented and you can identify any issues or conflicts beforehand.
Dig deeper: How to speed up site migrations with AI-powered redirect mapping
Assess existing redirects
If you keep a running redirect map, look back at previous redirects to see if your new ones will impact them at all.
For example, would you create a redirect chain or loop by adding new redirects to a page that already is redirected from another? This will also help you see if you have moved a page to a new URL several times over a short period of time.
If you do not have a map of previous redirects, you may be able to pull redirects from your server configuration files (or at least ask someone with access to it if they can!)
If you do not have access to the server configuration files either, or your redirects are implemented client-side, you can try the following techniques:
- Run your site through a crawling tool: Crawling tools mimic search bots in that they follow links and other signals on a website to discover all its pages. Many will also report back on the status code or if a meta refresh is detected on the URLs they find. Screaming Frog has a guide for detecting redirects using its tool.
- Use a plug-in: There are many browser plugins that will show if a page you are visiting has a redirect. They don’t tend to let you identify site-wide redirects, but they can be handy for spot-checking a page.
- Use Chrome Developer Tools: Another way, which just requires a Chrome browser, is to visit the page you are checking and use Chrome Developer Tools to identify if there is a redirect on it. You simply go to the Network panel to see what the response codes are for each element of the page. For more details, have a look at this guide by Aleyda Solis.
Google Search Console
The Coverage tab in Google Search Console lists errors found by Google that may prevent indexing.
Here, you may see examples of pages that have redirect errors. These are explained in further detail in Google’s Search Console Help section on Indexing reasons.
Alternatives to redirects
There are some occasions when redirects might not be possible at all. This tends to be when there is a limit to what can be accomplished through a CMS or with internal resources.
In these instances, alternatives could be considered. However, they may not achieve exactly what you would want from a redirect.
Canonical tags
To help rank a new page over the old one, you might need to use a canonical tag if redirects are not possible.
For example, you may have two identical URLs: Page A and Page B. Page B is new, but you want that to be what users find when they search with relevant search terms in Google. You do not want Page A to be served as a search result anymore.
Typically, you would just add a redirect from Page A to Page B so users could not access Page A from the SERPs. If you cannot add redirects, you can use a canonical tag to indicate to search engines that Page B should be served instead of Page A.
If URL A has been replaced by URL B and they both have identical content, Google may trust your canonical tag if all other signals also point to Page B being the new canonical version of the two.
Crypto redirects
A crypto redirect isn’t really a redirect at all. It’s actually a link on the page you would want to have redirected, directing users to the new page. Essentially it acts as a signpost.
For example, a call to action like, “This page has moved. Find it at its new location.” with the text linking to the content’s new URL.
Crypto redirects require users to carry out an action and will not work as a redirect for search engines, but if you are really struggling to implement a redirect and a change of address for content has occurred, this may be your only option to link one page to the other.
Conclusion
Redirects are useful tools for informing users and search engines that content has moved location. They help search engines understand the relevance of a new page to the old one while removing the requirement for users to locate the new content.
- Used properly, redirects can aid usability and search rankings.
- Used incorrectly, they can lead to problems with parsing, indexing and serving your website’s content.